
Three Point Perspective Drawing Examples
Three Point Perspective Drawing Examples - This will help you get the mechanics sorted out, and from there you can play with different angles and shapes. Three point perspective drawing multiple objects example. In this work, da vinci used linear perspective to create a sense of depth and space within the composition. Two going across the horizon line (hl) and the third going either below or above the horizon line. Web three point perspective is great when you wish to render objects or scenes from an abnormally high or low point of view.
The distortions that the third vanishing point brings into your composition often has a very artistic effect and makes even the most simple concept more interesting. See more ideas about perspective drawing, three point perspective, point perspective. Three point perspective is also used when drawing an object from a high eye level. In this work, da vinci used linear perspective to create a sense of depth and space within the composition. It is commonly used when drawing buildings from below or above the horizon. Web in three point perspective, the picture plane seems to be set at an angle as the viewer tends to tilt their head back or forward to look up or down from the eye level. One point perspective drawing lessons

A StepbyStep Tutorial on the Basics of ThreePoint Perspective Craftsy
Only this time, rather than in the middle, place the horizon line close to the top of your page if the viewer will be looking down, or the bottom of your. Web hey guys, this is the start of a new series of tutorials covering perspective drawing! See how to draw from a worm's eye.

3 point perspective drawing made simple
With a few simple tricks, you can be drawing like a pro! See more ideas about perspective drawing, three point perspective, point perspective. This will help you get the mechanics sorted out, and from there you can play with different angles and shapes. Web now we're going to draw a simple box in three point.

How to Draw Using ThreePoint Perspective Buildings Drawing Step by
All objects in the scene must converge at these vanishing points. Once you understand two point perspective, three point perspective is a slight adaptation to the technique. In this example, however, things get a little tricky when all of your vanishing points (vp’s) are off of the picture plane. A common use of three point.
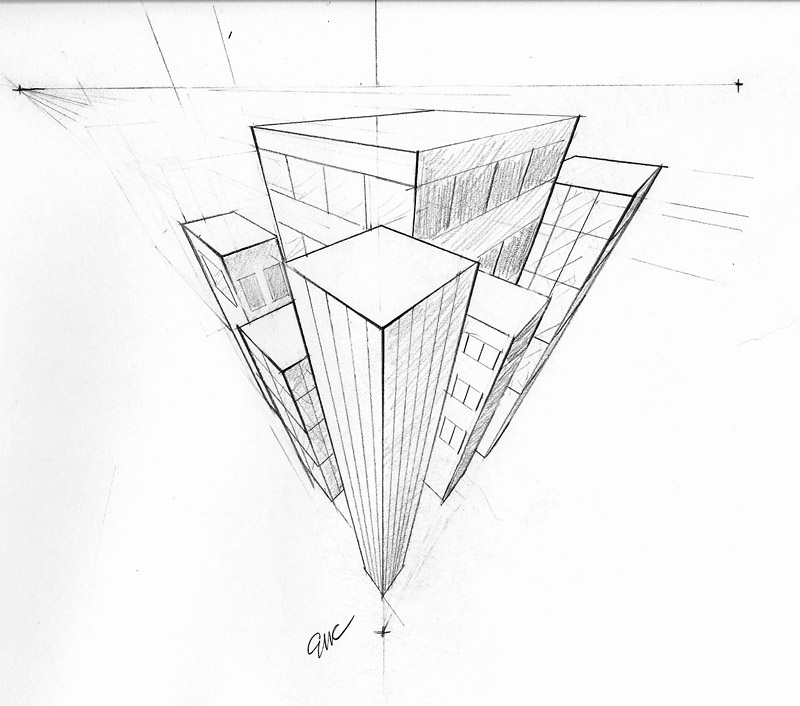
3 point perspective by ErinClayton on DeviantArt
7 when to use each type of perspective drawing; In this work, da vinci used linear perspective to create a sense of depth and space within the composition. There are two types of perspective: Web hey guys, this is the start of a new series of tutorials covering perspective drawing! Once you understand two point.

How To Draw ThreePoint Perspective Alvalyn Creative Three point
To begin with, we need a horizon line and three vanishing points — two on the horizon and one above us. By adding a third vanishing point either below or above one’s drawing an artist can convey the illusion of height in their artwork. Two going across the horizon line (hl) and the third going.

Three point perspective. Young art of Noble's Blog
6.1 drawing in a fisheye view; In this part, i'll talk about the basic perspective definitions & the drawing in 1,2,3 point perspective. Linear perspective and atmospheric perspective. Once you understand two point perspective, three point perspective is a slight adaptation to the technique. Web three point perspective is the most complex form of perspective.
:max_bytes(150000):strip_icc()/tower-3pt-perspective-56a26d143df78cf772758480.JPG)
Three Point Perspective Drawing Made Simple
Three point perspective uses three sets of orthogonal lines and three vanishing points to draw each object. Web now we're going to draw a simple box in three point perspective. The horizon line is situated very low. Web in three point perspective, the picture plane seems to be set at an angle as the viewer.
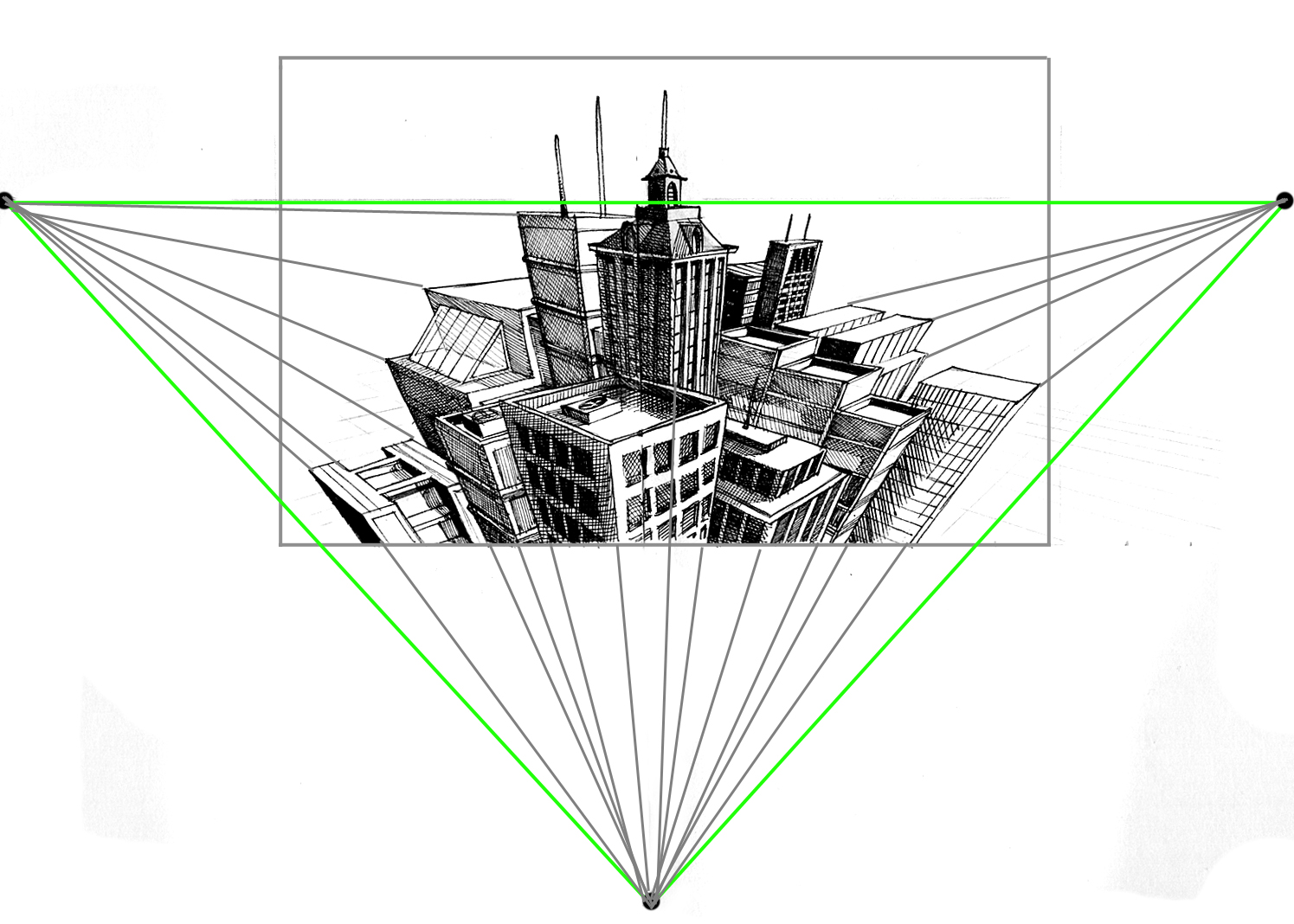
A StepbyStep Tutorial on the Basics of ThreePoint Perspective Craftsy
Once you understand two point perspective, three point perspective is a slight adaptation to the technique. Linear perspective and atmospheric perspective. In this work, da vinci used linear perspective to create a sense of depth and space within the composition. Imagine flying over a city and looking down at all the buildings. One point perspective.
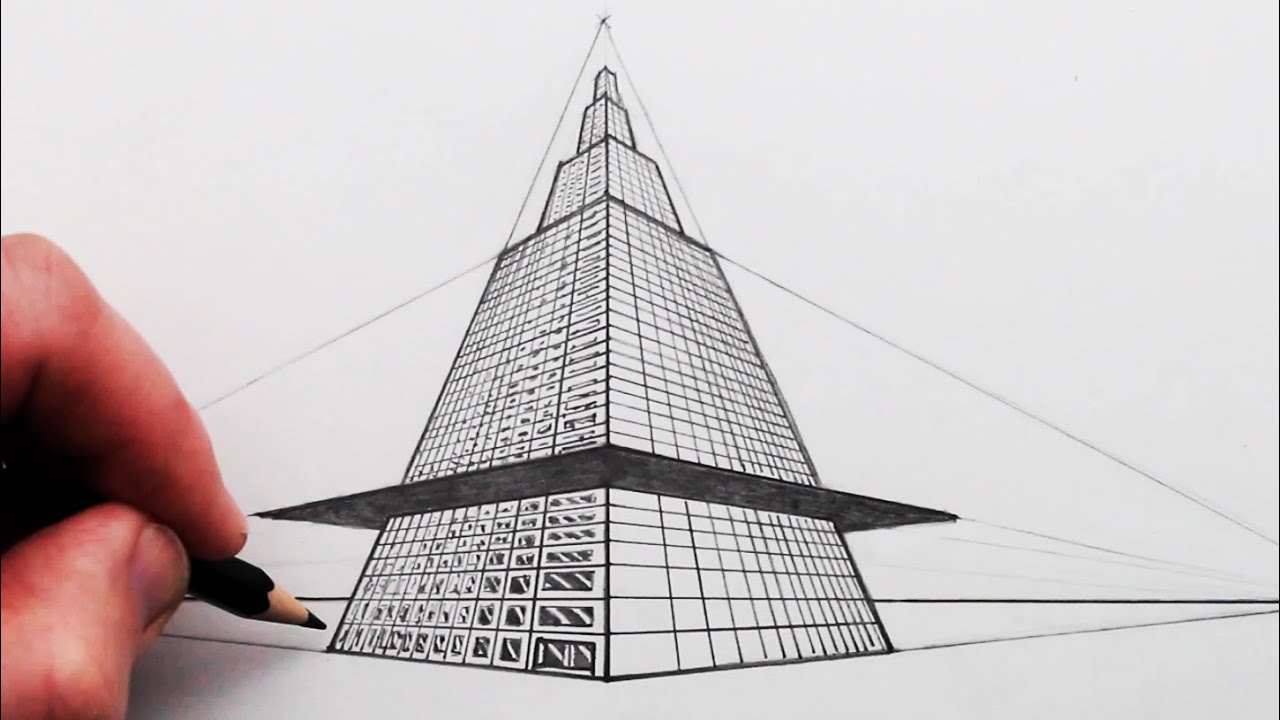
How to Draw 3Point Perspective Skyscraper Building YouTube
The distortions that the third vanishing point brings into your composition often has a very artistic effect and makes even the most simple concept more interesting. 6.1 drawing in a fisheye view; Three point perspective uses three sets of orthogonal lines and three vanishing points to draw each object. In this work, da vinci used.

Perspective Drawing Architecture, Perspective Drawing Lessons
In this part, i'll talk about the basic perspective definitions & the drawing in 1,2,3 point perspective. In this example, however, things get a little tricky when all of your vanishing points (vp’s) are off of the picture plane. Two going across the horizon line (hl) and the third going either below or above the.
Three Point Perspective Drawing Examples Web as the name implies 3 pt perspective drawing uses three vanishing points. In this part, i'll talk about the basic perspective definitions & the drawing in 1,2,3 point perspective. Web now we're going to draw a simple box in three point perspective. All objects in the scene must converge at these vanishing points. 5.1 drawing in a worm’s eye view;
Three Point Perspective From A High Eye Level.
In this part, i'll talk about the basic perspective definitions & the drawing in 1,2,3 point perspective. All objects in the scene must converge at these vanishing points. Three point perspective uses three sets of orthogonal lines and three vanishing points to draw each object. Web three point perspective building drawing example.
Basic Perspective Lessons For 1, 2, 3 Point Perspective Drawing Tutorials.
Imagine flying over a city and looking down at all the buildings. In this work, da vinci used linear perspective to create a sense of depth and space within the composition. When drawing multiple objects in three point perspective it may again be a good idea to first roughly sketch out the location of each. 7 when to use each type of perspective drawing;
Once You Understand Two Point Perspective, Three Point Perspective Is A Slight Adaptation To The Technique.
The horizon line is situated very low. 5.2 drawing in a bird’s eye view; This will help you get the mechanics sorted out, and from there you can play with different angles and shapes. Only this time, rather than in the middle, place the horizon line close to the top of your page if the viewer will be looking down, or the bottom of your.
Web In Three Point Perspective, The Picture Plane Seems To Be Set At An Angle As The Viewer Tends To Tilt Their Head Back Or Forward To Look Up Or Down From The Eye Level.
Start by marking your horizon line and placing your three vanishing points—two along the horizon and one either above or below it, depending on your viewpoint. To begin with, we need a horizon line and three vanishing points — two on the horizon and one above us. With a few simple tricks, you can be drawing like a pro! Web what is perspective drawing in art?